SWAR - SIMD-within-a-Register
Arithmetic for LEON and NOEL-V
Overview
The SIMD-within-a-register (SWAR) arithmetic extensions are targeted namely towards fixed-point applications that work with sub-word precision, e.g. 3 bits, such as satellite navigation applications, computation of neural networks in reduced integer precision or data encryption; the performance of the processor can be increased through an implementation of SIMD-like operations on variables that are stored alongside in one processor register, thus sharing the data-path circuitry for two or more operations executed in one clock cycle.
The SWAR instruction extensions are implemented as a SWAR unit that is connected in parallel to the integer ALU in the integer pipeline. The SWAR unit contains one or more SWAR modules and an optional module with SWAR accumulators.
At present six SWAR modules are available. Three application-specific modules are meant to accelerate GNSS processing:
- Correlation of GNSS signals (sum of products for 1-4 bit data words),
- Demodulation of GNSS signals (real and complex vector multiplication for 2-4 bit data words),
- Sine / cosine lookup for GNSS demodulation (lookup of 1-4 bit values for 32 bit arguments),
Three more generic modules that are meant to accelerate applications that work with up to 16-bit numbers and use mostly addition, subtraction and multiplication:
- Audio processing, data partitioned to 2x 16-bit words in one 32-bit register (ADD, SUB, MUL with optional reduction),
- Video processing, data partitioned to 4x 8-bit words in one 32-bit register (ADD, SUB, MUL with optional reduction),
- Generic ALU with user-defined data partitioning (ADD, SUB, MUL with optional reduction).
In addition accumulators can be used in connection with the audio ALU, video ALU or generic ALU modules; they have to be configured to fit the maximum number of lanes and maximum slice width over the selected SWAR ALU modules:
- up to 16 independent accumulator registers,
- each accumulator register up to 64 bits wide.
The user can specify register partitioning at synthesis time. The following picture shows an example of register partitioning for vector correlation.
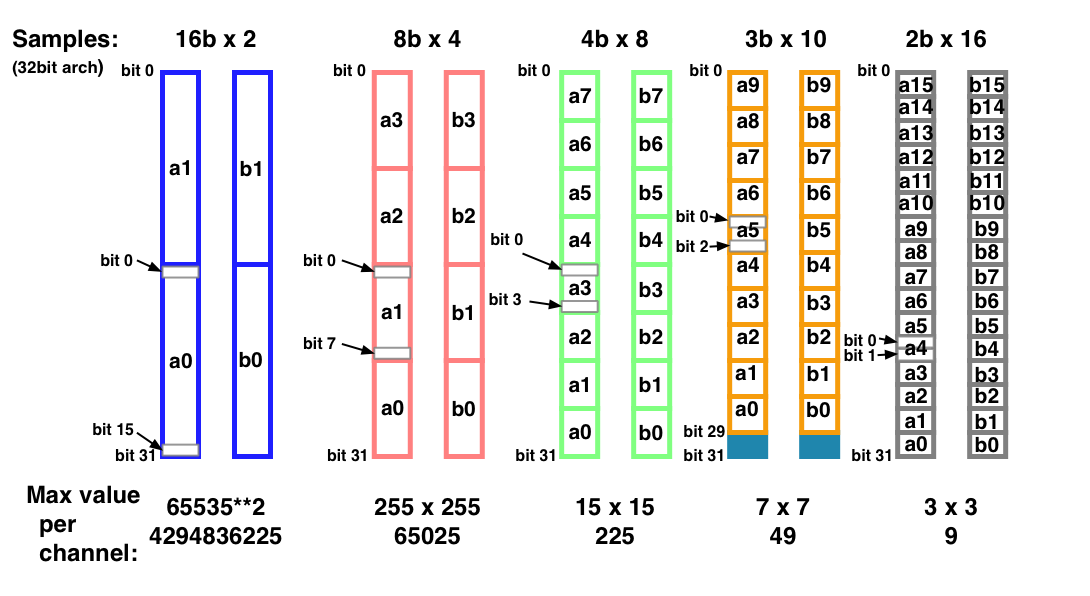
SWAR - mapping of subwords in source registers.
Validation
The SWAR unit has been validated in several independent ways:
- By hand-transforming the GNSS tracking loop code to work with 2-, 3- and 4-bit values, and by transforming elementary computation kernels into SWAR modules while verifying that the tracking loop can still decode bits of the navigation message. First the SWAR modules were represented by their functional models in C. The functional models were then replaced by actual SWAR modules implemented in VHDL.
- By validating SWAR modules developed in VHDL against their functional models writted in C.
By validating LEON2 and NOEL-V execution of the tracking loop, using the SWAR functional models in C or the actual SWAR modules in VHDL against desktop execution of the tracking loop using the SWAR functional models in C.
Availability
The SWAR unit IP core is provided in the form of a synthesizable VHDL code or FPGA netlist. It is available either separately or bundled together with the LEON2-FT processor or the NOEL-V processor.
For the bundled options a separate license has to be obtained from the European Space Agency for the LEON2-FT processor, or from Cobham Gaisler AB for the GRLIB / NOEL-V package.
The deliverables include:
- VHDL-RTL code or gate-level netlist,
- testing environment,
- simulation scripts,
- golden reference test vectors,
- synthesis scripts,
- user documentation.
The IP core is guaranteed against defects for ninety days from the date of purchase. Thirty days of technical support over email and phone is included. Additional support and maintenance options are available.
Hardware Compatibility
The SWAR unit is compatible with the following processors:
- LEON2 / LEON2-FT
- NOEL-V
Software Compatibility
The SWAR extensions are controlled through new user-defined data types in C programs. This requires the use of SPARCv8 or RISC-V llvm compiler and binutils with daiteq extensions. Alternatively, the SWAR extensions can be controlled directly with assembler instructions in C programs; this requires the use of a legacy SPARCv8 or RISC-V C compiler together with binutils with daiteq extensions.
Implentation Results
Indicative implementation results are provided for the SWAR unit both for a 32-bit processor architecture (LEON) and 64-bit processor architecture (NOEL-V) implemented in a Xilinx FPGA. For other FPGA families the results are similar.
Flavour |
LUTs |
Slice regs |
DSP48E1 |
|---|---|---|---|
swarall |
2941 |
253 |
9 |
swargnss-2b |
696 |
83 |
0 |
swargnss-3b |
760 |
78 |
0 |
swargnss-4b |
897 |
82 |
0 |
swaraudio |
310 |
98 |
2 |
swarvideo |
456 |
139 |
4 |
swaralu |
331 |
95 |
3 |
Identifier |
Logic LUTs |
DFFs |
DSPs |
|---|---|---|---|
swarall |
2420 |
1135 |
4 |
swargnss-2b |
124 |
72 |
0 |
swargnss-3b |
70 |
72 |
0 |
swargnss-4b |
62 |
72 |
0 |
swaraudio |
600 |
149 |
4 |
swarvideo |
440 |
148 |
4 |
swaralu |
388 |
101 |
6 |
GNSS Performance with SWAR Arithmetic
To evaluate a potential benefit of the SWAR extensions can be evaluated the following configurations of the GNSS tracking loop algorithm have been implemented and profiled:
- Octave-equivalent, i.e. all samples and computations in floating point, original USRP data file with complex samples coded using 2x 16 bits, buffered execution (store all intermediate results in arrays like in Octave). Computed correlation results are identical to those computed in Octave.
- Like the previous step, but navigation samples and the carrier wave (sine/cosine) values quantized to 2 bits.
- Samples quantized to 2b values, integer arguments for spreading code expansion and carrier generation, expand separate Early, Prompt, Late codes, do not use SWAR instructions, buffered execution
- Like the previous step, but use SWAR for demodulation
- Like the previous step, but use SWAR also for demodulation and correlation
- Like the previous step, but use SWAR also for sine/cosine lookup
- Samples quantized to 2b values, integer arguments for spreading code expansion and carrier generation, expand separate Early, Prompt, Late codes, use SWAR for sine/cosine lookup, demodulation and correlation, fused carrier generation and demodulation. Navigation samples are read from the FIFO and stored in a buffer at the beginning of the processing.
- Like the previous step, but all processing steps fused, i.e. carrier generation, demodulation and correlation. Navigation samples are read from the FIFO when needed (without buffering).
- Like the previous step, but expand just one spreading code and use it for all Early, Prompt and Late codes
- Like the previous step, but use HW support for spreading code expansion
The following table lists execution times for computing one iteration of the GNSS tracking loop in LEON2 with 2-bit GNSS SWAR extensions running in LEON2-FT at 25MHz after the indicated optimization steps were implemented in the algorithm. The table starts with a configuration that computed all floating-point operations in software and did not use any SWAR operations. The last row lists execution times for an implementation that used the daiFPU and the SWAR GNSS operations.
| Config | FIFO | Codes | Carrier | Demodulation | Correlation | Total |
|---|---|---|---|---|---|---|
| . | [us] | [us] | [us] | [us] | [us] | [us] |
| A - Original reference code, 2-bit values, SoftFloat | ||||||
| 2 | 63‘942 | 4‘874‘978 | 9‘624‘254 | 56‘033 | 108‘136 | 14‘530‘587 |
| B - like A plus SWAR instructions and daiFPU | ||||||
| 5 | 2‘343 | 82‘868 | 105‘190 | 9‘186 | 5‘771 | 208‘005 |
| 6 | 2‘430 | 82‘689 | 20‘601 | 9‘182 | 6‘204 | 121‘286 |
| C - like B plus fused steps | ||||||
| 7 | 2‘413 | 83‘874 | 20‘753 | 5‘812 | 113‘396 | |
| 8 | 83‘873 | 20‘129 | 6‘116 | 110‘118 | ||
| D - like C plus just one expanded code | ||||||
| 9 | 27‘772 | 18‘245 | 4‘366 | 50‘802 | ||
| 10 | 15‘286 | 18‘300 | 4‘501 | 38‘502 | ||
Additional information is available on request.